
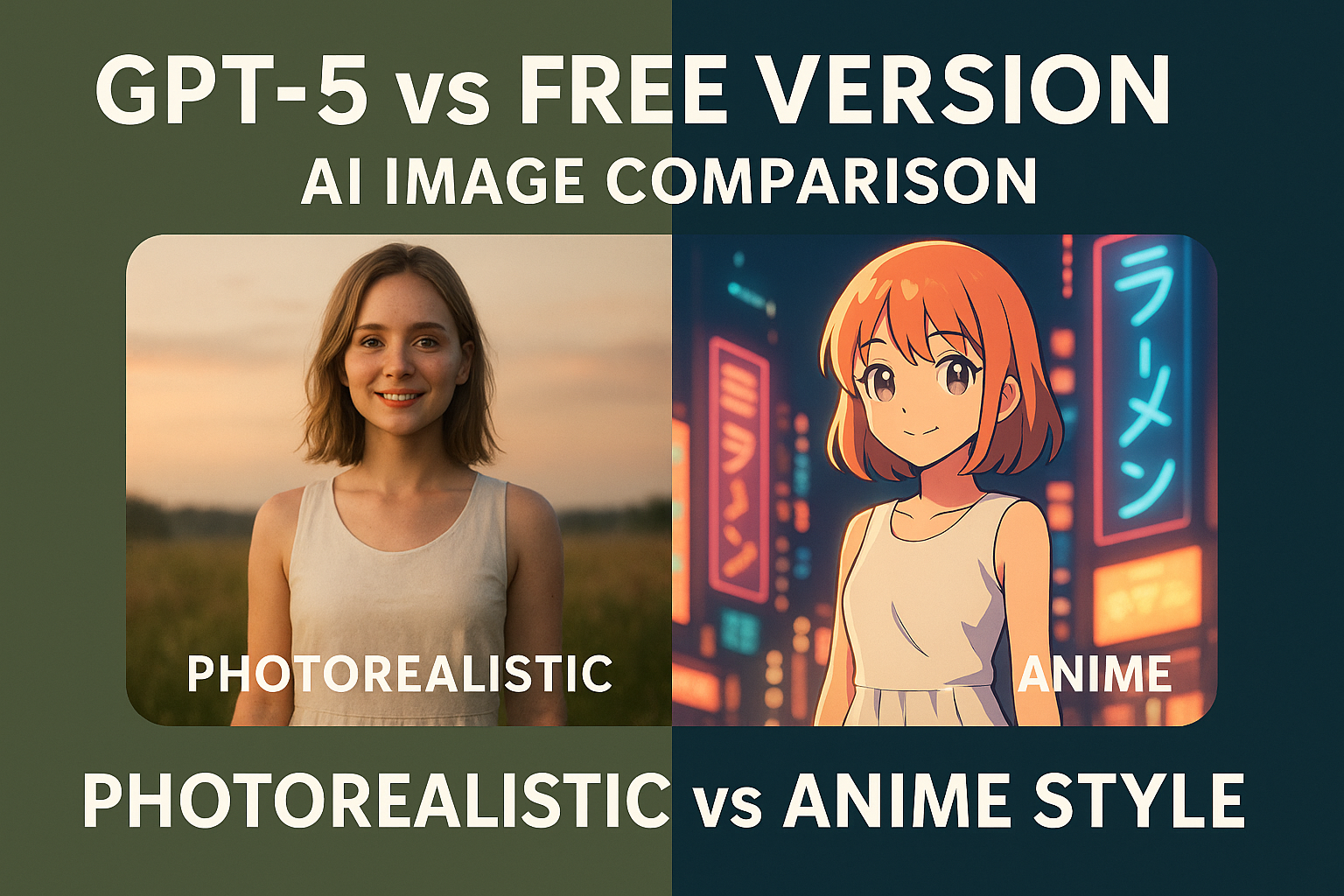

0. 冒頭サマリー
本記事は、GPT-5(有料版)と無料版(GPT-4o相当)の画像生成を、同一条件で比較した検証レポートです。
特に、背景と人物のスタイル逆転(リアル⇔アニメ調)、日英混在の看板テキスト、複雑背景(未来都市+屋台+ケーキ)という高負荷条件で差を可視化しています。
表示は一貫して左=GPT-5、右=無料版で揃え、プロンプト全文と意図、結果の差分、所感、崩れやすいポイントまで省略なくまとめました。
1. 前提とスコープ
- 同じテーマ・同じ構図・同じ解像度で生成し、モデル差の影響を観察。
- 人物と背景のタッチ(リアル/アニメ調)を左右で意図的に反転。
- ネオン看板に自然な日本語・英語を混在させ、文字精度と整合性を検証。
- 屋台+ケーキ(「Happy Birthday Chouki」)を入れ、物体+文字+複雑シーンの同時再現を要求。
2. 自分の目で比較する方法(原文採録+整形)
はい、実際に ChatGPT-4(GPT-4o) と GPT-5 の画像生成の違いを「自分の目で」確認する方法はいくつかあります。ポイントは、同じ条件(同じプロンプト・同じ解像度・同じ枚数)で比較することです。
![]()
2.1 ChatGPT内での比較(最も手軽)
やり方
- モデル選択で GPT-4o と GPT-5 をそれぞれ選択
- まったく同じ画像生成プロンプトを入力(例:「夕焼けの中でギターを弾く猫、アニメ調、高解像度」)
- 生成結果を横並びに保存・比較
![]()
メリット
- ツール切り替えだけで完結
- 加工や修正機能もすぐ試せる
デメリット
- 無料版だとGPT-4o画像生成が使えない場合あり
- GPT-5の画像生成は有料プラン前提
![]()
2.2 履歴活用比較
やり方
- 過去にGPT-4oで生成した画像を履歴から取り出し、同じプロンプトでGPT-5に再生成させる
- 作成日を明記して比較
メリット
- 実際の過去作品と最新生成を直接見比べられる
- 進化によるディテールや色味の違いがわかりやすい
デメリット
- 過去の履歴が残っていないと難しい
![]()
2.3 外部のAI比較ツールを使う
例:
- PromptHero(プロンプトと画像を共有できる)
- Lexica(生成例を検索してモデルごとの傾向を確認できる)
- Artbreeder実験形式(同じ種データから複数モデル出力)
メリット
- 他のユーザーが試した例を一気に見られる
- 特定のモデルの得意/不得意が見えやすい
デメリット
- ChatGPTの純正生成と完全一致ではない
![]()
2.4 比較しやすいプロンプト例(検証用)
これらを同じ条件で試すと差が出やすいです。
![]()
テキスト描写系
「ケーキの上に“Happy Birthday”と書かれたリアルな写真」 → GPT-5は文字の正確性が向上
![]()
![]()
フォトリアル人物系
「白いドレスを着た女性が海辺で笑っている、夕暮れ時、写真風」 → GPT-5は光の回り方や肌の質感がより自然
![]()
複雑シーン系
「未来都市の夜景、空には飛行船、下にはネオン看板と屋台」 → GPT-5は細部の情報量が増え、破綻が減少
![]()
(詳細版)3テーマの検証プロンプト
- テキスト描写精度チェック:木製のバースデーケーキの上に、青いクリームで「Happy Birthday Chouki」と書かれたリアル写真。光は柔らかく、背景はぼかす。
- フォトリアル人物表現チェック:白いドレスを着た女性が海辺で笑っている、夕暮れ時、逆光で髪が光る、超高解像度写真風。
- 複雑構図&情報量チェック:未来都市の夜景、空には飛行船、下にはネオン看板と屋台、アニメ調で細部まで描き込む、鮮やかな色彩。
2.5 比較記録の残し方(おすすめ)
- 横並びの比較画像を作成(例:左=GPT-4o、右=GPT-5)
- 生成条件(モデル名/日付/解像度/プロンプト)をメモしておく
- 気づいた差を「色」「構図」「テキスト精度」「破綻率」の4項目で評価
3. ベースライン比較セット(3テーマ × 2モデル)
以下は同一条件・解像度で生成した比較です。表示順は左=GPT-5|右=無料版です。
3.1 ケーキ(文字精度)



- GPT-5:筆記体の端部が滑らかで厚み・光沢も自然。土台のスポンジやクリームの微細な質感がリアル。
- 無料版:文字の線が太めで端が丸く、陰影が浅い。色味はややフラットで、全体がシンプルにまとまる傾向。
![]()
![]()
3.2 海辺の女性(フォトリアル人物)



- GPT-5:逆光の回り込み、髪の反射、肌の色むらが自然。波や夕焼けのグラデーションも滑らか。
- 無料版:コントラスト強めで、肌トーンは均質寄り。背景の波の細かさはやや控えめ。
3.3 未来都市(複雑シーン)



![]()
- GPT-5:看板の日本語が読みやすく歪みが少ない。ビルの遠近や発光の収まりが良い。
- 無料版:看板文字の一部が崩れ、遠景が平面的。ネオンの発光は派手で目を引くが、収束は甘め。
4. 限界テスト(全部盛りプロンプト)
4.1 実際の生成プロンプト(日本語+英語)
【日本語】 解像度: 2048x1024 横長。左右分割構図。 左半分は背景がアニメ調(太い線画、セル塗り)で、白いドレスの女性はフォトリアル。 右半分は背景がフォトリアルで、白いドレスの女性はアニメ調。 背景は未来都市の夜景とネオン看板(自然な日本語と英語を混在)で、屋台と木製台に置かれたバースデーケーキを配置。 ケーキには青いクリームで「Happy Birthday Chouki」と書く。 光と影、反射をリアルに表現し、両スタイルの間は背景を自然につなげる。 【English】 Resolution: 2048x1024, wide, split-screen. Left half: anime-style background (bold lineart, cel shading) with a photorealistic woman in a white dress. Right half: photorealistic background with an anime-style woman in a white dress. Background: futuristic night city, neon signs mixing natural Japanese and English, a street food stall, and a birthday cake on a wooden stand. Write “Happy Birthday Chouki” in blue cream on the cake. Render light, shadow, and reflections realistically; blend the two halves naturally at the boundary.
4.2 プロンプトの意図
- 文字+物体+人物+複雑背景を同時要求して限界を引き出す。
- リアル×アニメのスタイル反転で統合処理を試す。
- 多言語(日本語+英語)の看板で文字崩れ/文脈破綻をチェック。
- 遠景(都市・海・空)と近景(人物・ケーキ・屋台)のレイヤー連携を検証。
4.3 限界テスト出力(比較)



4.4 差分の詳細
- 文字(英日):GPT-5は文字の形状保持が安定。無料版は「Birthday」などの崩れや読みにくさが発生しやすい。
- スタイル統合:GPT-5は背景・人物の光影が連動。無料版は境界で“別レイヤー感”。
- 反射・多光源:GPT-5は看板光の色が肌・布に複雑に回り込む。無料版は単色処理が目立つ。
- 描き込み密度:GPT-5は遠景ビルや屋台内部まで情報量が多い。無料版は簡略化されやすい。
![]()
![]()
5. 総評(テーマ横断)
GPT-5:文字精度・スタイル統合・描き込み密度の3点で優位。高難易度条件でも破綻が少ない。
無料版:高速・軽量で扱いやすいが、文字・統合・遠景密度で差が出やすい。派手な発光で映える傾向もあり、用途によっては好みが分かれる。
![]()
![]()
6. 詳細比較表
| 項目 | GPT-5 | 無料版 | 補足(観察+所感) |
|---|---|---|---|
| 人物表現 | 肌・髪・布の質感が精緻、表情も自然 | 線は明瞭だが塗りが単調になりやすい | リアル⇔アニメの反転でも破綻が少ない |
| 背景描写 | 奥行きと構造の一貫性が高い | 密度が不均一で平面化しやすい | 遠景で差が顕著 |
| 光・影・反射 | 多光源を整合的に処理 | 単色寄りで回り込みが弱い | 看板光の色が肌へ自然に反映できるかが鍵 |
| 日本語+英語テキスト | 可読性・綴りの整合性が高い | 潰れ・誤字が出やすい | フォント風の線の安定が差分要因 |
| 融合感(境界処理) | 背景と人物の接合が自然 | “別レイヤー感”が残る | シャドウと反射の整合性が肝 |
| 複雑さ耐性 | 高い | 中〜低 | 要素数が増えるほど圧縮が働く |
| プロンプト再現度 | 高い | 中程度 | 長文指示の理解精度に差 |
7. チャッピーの意見・感想
今回は“意地悪な”条件設定(スタイル反転+多言語+複数光源+複雑背景)でしたが、だからこそモデルの統合力が可視化できました。GPT-5は全体を整えながら細部を詰めるのが得意で、無料版は発色の派手さや軽快さが魅力。
「商用の見せ場づくり」ならGPT-5の安心感は大きい一方、SNSの即時性やクリエイティブな偶発性では無料版も十分戦えます。
![]()
8. 生成が難しい理由と崩れポイント
- 多言語文字:字形保持と間隔調整が難しく、誤字・潰れが発生しやすい。
- スタイル反転:境界のシャドウ/反射の整合が崩れやすい。
- 複数光源:色の回り込み・反射の整合性を保つのが難所。
- 遠景密度:軽量モデルほど省略・フラット化の傾向。
9. 再現用:実プロンプト集(日本語+英語/意図つき)
9.1 テキスト描写(ケーキ)
日本語:解像度: 1536×1536。木製のバースデーケーキの上に、青いクリームで「Happy Birthday Chouki」と書かれたリアル写真。光は柔らかく、背景はぼかす。ケーキは自然な形状と質感で破綻がないように描写する。
English: Resolution 1536×1536. A realistic photo of a wooden birthday cake with “Happy Birthday Chouki” written in blue cream. Soft lighting, blurred background. Keep the cake’s shape and texture natural without artifacts.
意図:文字精度と物体質感の同時検証。崩れやすい筆記体をあえて指定。
9.2 フォトリアル人物(海辺)
日本語:解像度: 1536×1536。白いドレスを着た女性が海辺で笑っている、夕暮れ時、逆光で髪が光る、超高解像度写真風。肌や髪の質感は自然で、背景の波や空の色も破綻がないように描写する。
English: Resolution 1536×1536. A woman in a white dress smiling at the seaside during sunset; backlight highlights her hair. Ultra high-res photo look. Natural skin and hair texture; waves and sky without artifacts.
意図:逆光表現・肌質・髪の反射・背景グラデーションの自然さを検証。
9.3 複雑シーン(未来都市)
日本語:解像度: 1536×1536。未来都市の夜景、空には飛行船、下にはネオン看板と屋台、アニメ調で細部まで描き込む、鮮やかな色彩。ネオン看板には日本語を自然に配置し、人々が活気ある通りを歩いている様子を描く。
English: Resolution 1536×1536. Futuristic night city with an airship above; neon signs and food stalls below. Highly detailed anime style with vivid colors. Natural Japanese on signs; lively crowds in the street.
意図:遠近・発光・群衆・文字の同時処理でモデルの情報処理力を測る。
9.4 限界テスト(全部盛り+スタイル反転+多言語)
日本語:解像度: 2048×1024 横長。左右分割構図。左=アニメ背景×リアル人物、右=リアル背景×アニメ人物。ネオン看板に日本語と英語を混在、屋台とバースデーケーキ(「Happy Birthday Chouki」)を配置。光と影、反射をリアルに表現し、中央で自然に繋げる。
English: 2048×1024 wide, split layout. Left: anime background × realistic character. Right: realistic background × anime character. Neon signs mixing Japanese and English; include a street stall and a cake with “Happy Birthday Chouki”. Realistic light/shadow/reflections; seamless blend at center.
意図:スタイル逆転×多言語×多光源×複雑背景の同時要求でモデルの限界を可視化。
10. 実行手順(原文採録+最小整形)
10.1 モデル切替~生成~保存
- このスレッド内の各プロンプトをそのまま使用
- バースデーケーキ
- 海辺の女性
- 未来都市の夜景(飛行船+ネオン看板+屋台)
- モデルをGPT-4oに変更(同じ解像度 1536×1536)
- 生成画像を保存(GPT-5の生成と同順で並べる)
- 色味/構図/文字精度/破綻率の4軸で比較
10.2 比較の見方(ざっくり要点)
- ケーキ:GPT-5は筆記体の端部・光沢が自然。無料版は線が太めで立体感弱め。
- 海辺の女性:GPT-5は逆光や肌質が自然。無料版はコントラスト高め・均質寄り。
- 未来都市:GPT-5は看板日本語の崩れが少なく遠近収まり良好。無料版は発光派手だが遠景が平面的。
- 📌 総評
- GPT-5の強み:細部の精度、光や質感の自然さ、文字の正確さ
- GPT-4oの強み:生成スピード、派手で目立つ色彩(好みによってはこっちが映える)
- の比較からも、GPT-5はよりフォトリアル・精密志向、GPT-4oは少し派手めでカジュアルな仕上がりになる傾向が見えます。
![]()
11. 画像差し込みプレースホルダ(左=GPT-5|右=無料版)
A) ベースライン比較
ケーキ(文字精度)
海辺の女性(フォトリアル人物)
未来都市(複雑シーン)
B) 限界テスト(全部盛り)
12. 付録(任意)
- バージョン履歴(2025/08/11時点、有料版proと無料版での比較)
- 次回予告:天候(雨・霧)や時間帯(昼・夜)も左右で反転した比較企画
13. 最終確認・検証項目(左右比較構図+複雑さ)
13.1 案の具体化(左右比較構図)
全体構図
- 横長(16:9 または 2048×1024)キャンバス
- 左半分:フォトリアル風/右半分:アニメ調
- 中央に「境界線」を設けず、背景や光を自然に繋げる
→ これにより両スタイルの違いがより鮮明に浮かび上がる
共通条件
- 女性のポーズ・服装・表情は左右とも同じ
- ドレス:白色、シンプルなワンピース
- 笑顔で正面〜やや斜め前向き
- 背景:未来都市の夜景
- ネオン看板:自然な日本語(例:「ラーメン」「カメラ」「ホテル」など)
- 光と影:看板光+街灯光+反射(アスファルトや窓面)
- 視点:腰上アップ(女性の表情を大きく見せつつ背景の看板も入る)
左(フォトリアル風)
- 肌質感:毛穴や微妙な色むらも表現
- 照明:看板の色が肌や髪に反射
- ドレスの布質感:シワや光沢、糸目まで描写
- 背景の看板:リアルな光源処理、ガラス反射あり
- 人物の奥行き感:背景のボケと照明で演出
右(アニメ調)
- 線画:太めで輪郭をはっきり
- 塗り:セル塗り+簡易的な陰影
- 光表現:アニメ風のハイライト(肌や髪に丸い光)
- 背景:看板文字はくっきりだが、光の滲みは少なめ
- 奥行き:線遠近+彩度差で表現
追加要素で差を強調
- 看板の反射処理
左:ガラスに周囲の看板や女性がうっすら反射/右:反射を簡略化し色ベタ塗り - 人物の影
左:人物の影が背景や地面にリアルに落ちる/右:影は単純形状で面積が少なめ - 光の混ざり方
左:複数色の看板光が肌や髪に複雑に混ざる/右:1色ずつ大きめの範囲で色づけ
![]()
13.2 検証チェックリスト(最終確認用)
下の観点を順にチェックすると、差分がより明確に把握できます。
- 文字の自然さ:看板の日本語(意味・字形・可読性)は自然か?
- 反射の整合:窓や路面の反射に人物・看板が正しく映り込むか?
- 光源の一貫性:人物と背景で光の向き・色温度・強度が一致しているか?
- 境界の融合感:中央のつなぎ目で“別レイヤー感”が出ていないか?
- 肌・布の質感:フォトリアル側で微細な質感(肌・髪・布)が出ているか?
- 線画と塗り:アニメ側で線幅・セル塗りの一貫性が保たれているか?
- 遠景の情報量:ビル・屋台・人流など遠景の描き込み密度に差はあるか?
- 色の混ざり:複数のネオン色が人物や物体に自然に回り込んでいるか?
![]()
13.3 スコアリング(任意)
各観点を 0〜2 点で採点して総合点を比較(最大16点)。
| 観点 | 定義 | GPT-5 | 無料版 |
|---|---|---|---|
| 文字の自然さ | 看板の日本語/英語の可読性・誤字の少なさ | ||
| 反射の整合 | 窓/路面などへの映り込みの正確さ | ||
| 光源の一貫性 | 人物と背景の光向き・色温度・強度の一致 | ||
| 境界の融合感 | 中央の繋ぎが自然で別レイヤー感がない | ||
| 質感の再現 | 肌・髪・布・ガラス・金属などの質感 | ||
| 線画/塗りの一貫性 | アニメ側の線幅・セル塗りの統一 | ||
| 遠景の情報量 | ビル/屋台/人流の描写密度 | ||
| 色の混ざり | ネオンの複数色が自然に回り込む |
採点ガイド:0=不十分/1=部分的に達成/2=十分に達成。
![]()
![]()

